
오늘은 회사에서 일을 하던 중
내가 짠 쿼리가 운영환경에서 10초이상 걸리며 오래 걸렸던 문제를
해결한 경험을 공유하고자 한다.
쿼리는 아래와 같은 카운트 쿼리에 데이터는 약 수억건이 있는 테이블이였다.
(테이블명이나 컬럼명 등은 변경한 상태이니 양해바란다)
SELECT
COUNT(id)
FROM
member
WHERE
(created_at >= '2020-03-25 00:00:00.0'
AND created_at < '2020-03-26 00:00:00.0')
데이터가 많이 없는 테이블에서 위와같은 카운트쿼리는 크게 문제되지 않겠지만
내가 쿼리를 날린 테이블은 수억건이 있기 때문에 조회를 할 때는 무조건 인덱스를 활용해서 날려야 한다.
그런데 이 member 테이블에는 간단하게 id, name, created_at 의 3개의 컬럼과
아래와 같이 index가 구성되어 있다고 해보자.
| 인덱스명 | 인덱스를 구성하는 키 |
| pk | id |
| idx_name_created_at | 1: name 2: created_at |
인덱스 구성을 보면 왜 쿼리 성능이 안좋았는지 감이 오시는 분들도 많을 것이다.
이유는 복합인덱스 키를 제대로 활용하지 못했기 때문이다.
복합인덱스를 구성하게 되면
첫번째 키로 데이터들을 정렬한 다음 첫번째 키가 같은 컬럼은 두번째 키로 정렬하는 식으로 인덱스를 구성하게 된다.
엑셀이긴 한데 아래와 같이 정렬한다고 이해하면 될 것 같다.
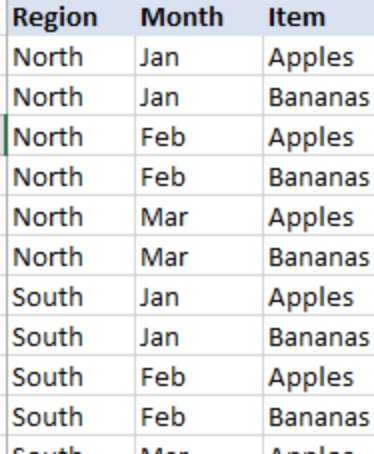
그러니 두번째 컬럼에 해당하는 created_at 을 조건으로 주었을 때
인덱스에는 해당 칼럼대로 정렬되어있지 않았을 것이고
mysql 의 쿼리 실행을 담당하는 옵티마이저는 어쩔수 없이 쭉 아래까지 뒤져보며 풀스캔을 할 수밖에 없었던 것이다.
따라서 구성한 복합 인덱스를 잘 활용하기 위해서는 아래와 같이 쿼리를 날리면 될 것이다.
SELECT
COUNT(id)
FROM
member
WHERE
name='tom'
AND (created_at >= '2020-03-25 00:00:00.0'
AND created_at < '2020-03-26 00:00:00.0')
이렇게 날리면 name 으로 인덱스에서 후보군을 추려낸 다음
created_at 조건으로 빠르게 해당하는 데이터를 셀 수 있다.
혹여나 where문에서 name 과 craeated_at의 순서를 바꿔서 날리는 일이 없기를 바란다.
그러면 옵티마이저는 또 인덱스를 탈지 안탈지 헷갈려하며 풀스캔을 시작할수도 있다.
인덱스를 만들 때는 최대한 용도를 잘 생각해서 신중하게 만들고
만들었다면 최대한 잘 활용하기 위한 쿼리를 짜기 위해 노력하자
또, 쿼리를 짜고나면 explain 을 걸어
내가 짠 쿼리를 옵티마이저가 어떻게 실행하고자 하는지 쿼리 실행계획을 꼭 한번씩 확인하는 습관을 가지자!
'에러해결 & 최적화 > DB' 카테고리의 다른 글
| [쿼리튜닝]where문에 cast를 쓰면 안되는 이유 (1) | 2023.11.03 |
|---|---|
| 인덱스 설계를 통한 쿼리속도 튜닝하기 (0) | 2023.10.31 |
| 쿼리튜닝의 핵심, 옵티마이저에 대해서 (0) | 2023.10.30 |
| 데이터베이스 쿼리 실행 계획 확인: 성능 최적화의 핵심 (2) | 2023.10.29 |
| SQL 쿼리 튜닝하는 여러가지 방법 (1) | 2023.02.27 |